Kettle5.4统计各部门工资总额
本文共 1426 字,大约阅读时间需要 4 分钟。
Kettle5.4统计各部门工资总额
实验环境及配置
- 版本:hadoop-2.7.3
- 模式:伪分布式
- 网络模式:NAT
- 虚拟机ip:192.168.215.135(读者根据自己得实际情况修改)
- 虚拟机主机名称:hadoop001
- 虚拟机内存:4G
kettle版本5.4(由于虚拟机内存有限,尽量使用低版本的)- kettle环境安装及配置(参考之前的博客)
一、任务说明
- 利用Kettle设计实现求出各个部分员工工资总和。
- 测试数据:
二、设计转换和作业
-
设计mapper的转换
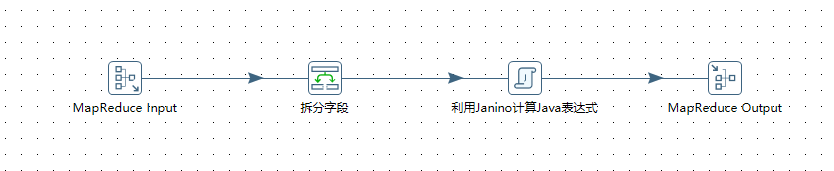
-
设计reducer转换
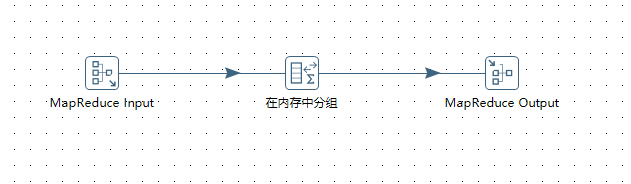
-
设计Job作业

三、配置转换和作业
-
配置mapper转换
-
上图所示中的 "Input"指的是左边菜单栏中Big Data菜单下的MapReduce Input 组件,双击进行编辑:

-
上图所示中的"拆分字段" 指的是左边菜单栏中“转换”菜单下的“拆分字段”组件,双击进行编辑:注意: 其中的"字段名称":可以任意取名的,按照如图进行配置

-
上图所示中的"利用Janino计算Java表达式" 指的是左边菜单栏中"脚本"菜单下的“利用Janino计算Java表达式” 组件,双击进行编辑:

-
配置“利用Janino计算Java表达式",如下所示:

-
上图所示中的

-
-
配置reducer转换
-
根据设计图,图中的 "Input"指的是左边菜单栏中Big Data菜单下的MapReduce Input 组件,双击进行编辑:

-
上图所示中的"在内存进行分组" 指的是左边菜单栏中"统计"菜单下的“在内存进行分组” 组件,双击进行编辑:

-
上图所示中的"ouput" 指的是左边菜单栏中Big Data菜单下的MapReduce Output 组件,双击进行编辑:

-
-
配置Job作业
- 上图所示中的"START" 指的是左边菜单栏中"通用"菜单下的START组件,如下所示:
- 上图所示中的"Pentaho MapReduce" 指的是左边菜单栏中Big Data菜单下的Pentaho MapReduce组件,双击进行编辑:
-
【A】配置Hadoop Cluster:
 特别注意: 如下配置,如果在Windows上(C:\Windows\System32\drivers\etc\hosts)配置了虚拟机主机名称和虚拟机的IP映射关系,则如下配置写IP地址或者主机名称都可以
特别注意: 如下配置,如果在Windows上(C:\Windows\System32\drivers\etc\hosts)配置了虚拟机主机名称和虚拟机的IP映射关系,则如下配置写IP地址或者主机名称都可以 
-
【B】配置Mapper,把之前新建的mapper的转换放进来

-
【C】配置reducer,把之前新建的reducer的转换放进来

-
【D】配置Job Setup


-
【E】配置Cluster,选择自己新建的Hadoop Cluster即可

-
- 上图所示中的"START" 指的是左边菜单栏中"通用"菜单下的START组件,如下所示:
四、运行转换和作业
- 前提: 运行前,务必确保hadoop集群已经启动,并且HDFS上input目录下有文件,我的文件是testData.txt,文件内容就是前文所述的【测试数据】
- 选择job任务,切换到job视图后,点击kettle工作区顶部的启动按钮,在弹窗中,点击执行按钮
- 运行

五、查看结果
-
在kettle控制台查看结果:


-
在Hadoop上查看结果,即查看Yarn容器上是否接收到该任务:
 等待执行结束!
等待执行结束! -
成功后的查看结果: 如成功,则可以查看下HDFS上的结果:
执行: hdfs dfs -cat /user/root/mr/emp/part-00000 如不成功,请查看报错日志,解决错误后,请在继续上述步骤 我的成功了,可以喝杯咖啡去咯祝大家好运!!!!!
如不成功,请查看报错日志,解决错误后,请在继续上述步骤 我的成功了,可以喝杯咖啡去咯祝大家好运!!!!!
转载地址:http://rkpti.baihongyu.com/
你可能感兴趣的文章
[LeetCode]Combination Sum II
查看>>
[LeetCode]Combinations
查看>>
[LeetCode]Construct Binary Tree from Inorder and Postorder Traversal
查看>>
[LeetCode]Convert Sorted Array to Binary Search Tree
查看>>
[LeetCode]Longest Valid Parentheses
查看>>
[LeetCode]Maximal Rectangle
查看>>
[LeetCode]Maximum Subarray
查看>>
[LeetCode]Median of Two Sorted Arrays
查看>>
[LeetCode]Merge Intervals
查看>>
[LeetCode]Merge k Sorted Lists
查看>>
[LeetCode]Merge Sorted Array
查看>>
[LeetCode]Merge Two Sorted Lists
查看>>
[LeetCode]Minimum Depth of Binary Tree
查看>>
[LeetCode]Minimum Path Sum
查看>>
[LeetCode]Minimum Window Substring
查看>>
[LeetCode]Multiply Strings
查看>>
[LeetCode]N-Queens II
查看>>
[LeetCode]Next Permutation
查看>>
[LeetCode]Palindrome Number
查看>>
[LeetCode]Palindrome Partitioning
查看>>